除了训练和测试脚本,我们在 tools/ 文件夹内还提供了一些有用的工具。
日志分析¶
tools/analysis_tools/analyze_logs.py 通过给定的日志文件绘制 loss/mAP 曲线。 需首先执行 pip install seaborn 安装依赖。
python tools/analysis_tools/analyze_logs.py plot_curve [--keys ${KEYS}] [--title ${TITLE}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
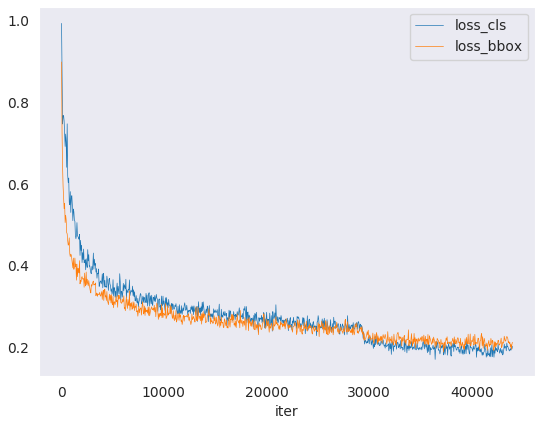
示例:
绘制某次执行的分类损失
python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls --legend loss_cls
绘制某次执行的分类和回归损失,同时将图像保存到 pdf 文件
python tools/analysis_tools/analyze_logs.py plot_curve log.json --keys loss_cls loss_bbox --out losses.pdf
在同一张图像中比较两次执行的 mAP
python tools/analysis_tools/analyze_logs.py plot_curve log1.json log2.json --keys bbox_mAP --legend run1 run2
计算平均训练速度
python tools/analysis_tools/analyze_logs.py cal_train_time log.json [--include-outliers]
预计输出如下
-----Analyze train time of work_dirs/some_exp/20190611_192040.log.json----- slowest epoch 11, average time is 1.2024 fastest epoch 1, average time is 1.1909 time std over epochs is 0.0028 average iter time: 1.1959 s/iter
可视化¶
可视化数据集¶
tools/misc/browse_dataset.py 帮助用户浏览检测的数据集(包括图像和检测框的标注),或将图像保存到指定目录。
python tools/misc/browse_dataset.py ${CONFIG} [-h] [--skip-type ${SKIP_TYPE[SKIP_TYPE...]}] [--output-dir ${OUTPUT_DIR}] [--not-show] [--show-interval ${SHOW_INTERVAL}]
模型复杂度¶
tools/analysis_tools/get_flops.py 是改编自 flops-counter.pytorch 的脚本,用于计算给定模型的 FLOPs 和参数量。
python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
预计输出如下
==============================
Input shape: (3, 1024, 1024)
Flops: 215.92 GFLOPs
Params: 36.42 M
==============================
注意: 此工具仍处于实验阶段,我们并不能保证计算结果是绝对正确的。你可以将结果用于简单的比较, 但在技术报告或论文中采用之前请仔细检查
FLOPs 与输入大小相关,但参数量与其无关。默认输入大小是(1, 3, 1024, 1024)。
一些算子例如 DCN 或自定义算子并未包含在 FLOPs 计算中,所以 S2A-Net 和基于 RepPoints 的模型的 FLOPs 计算是错误的。 详细信息请查看
mmcv.cnn.get_model_complexity_info()。两阶段检测器的 FLOPs 取决于候选的数量。
准备发布模型¶
tools/model_converters/publish_model.py 帮助用户准备他们将发布的模型。
在将模型上传到 AWS 之前,你可能需要
将模型权重转换至 CPU
删除优化器的状态
计算权重文件的哈希值并附加到文件名后
python tools/model_converters/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
例如,
python tools/model_converters/publish_model.py work_dirs/rotated_faster_rcnn/latest.pth rotated_faster_rcnn_r50_fpn_1x_dota_le90_20190801.pth
最终输出的文件名是 rotated_faster_rcnn_r50_fpn_1x_dota_le90_20190801-{hash id}.pth。
基准测试¶
FPS 基准¶
tools/analysis_tools/benchmark.py 帮助用户计算 FPS。 FPS 值包括模型前向传播和后处理。为了得到更准确的数值,目前只支持单 GPU 分布式启动。
python -m torch.distributed.launch --nproc_per_node=1 --master_port=${PORT} tools/analysis_tools/benchmark.py \
${CONFIG} \
${CHECKPOINT} \
[--repeat-num ${REPEAT_NUM}] \
[--max-iter ${MAX_ITER}] \
[--log-interval ${LOG_INTERVAL}] \
--launcher pytorch
示例: 假设你已经下载了 Rotated Faster R-CNN 模型权重到 checkpoints/ 文件夹
python -m torch.distributed.launch --nproc_per_node=1 --master_port=29500 tools/analysis_tools/benchmark.py \
configs/rotated_faster_rcnn/rotated_faster_rcnn_r50_fpn_1x_dota_le90.py \
checkpoints/rotated_faster_rcnn_r50_fpn_1x_dota_le90-0393aa5c.pth \
--launcher pytorch
杂项¶
打印完整配置文件¶
tools/misc/print_config.py 输出整个配置文件并整合其所有导入。
python tools/misc/print_config.py ${CONFIG} [-h] [--options ${OPTIONS [OPTIONS...]}]
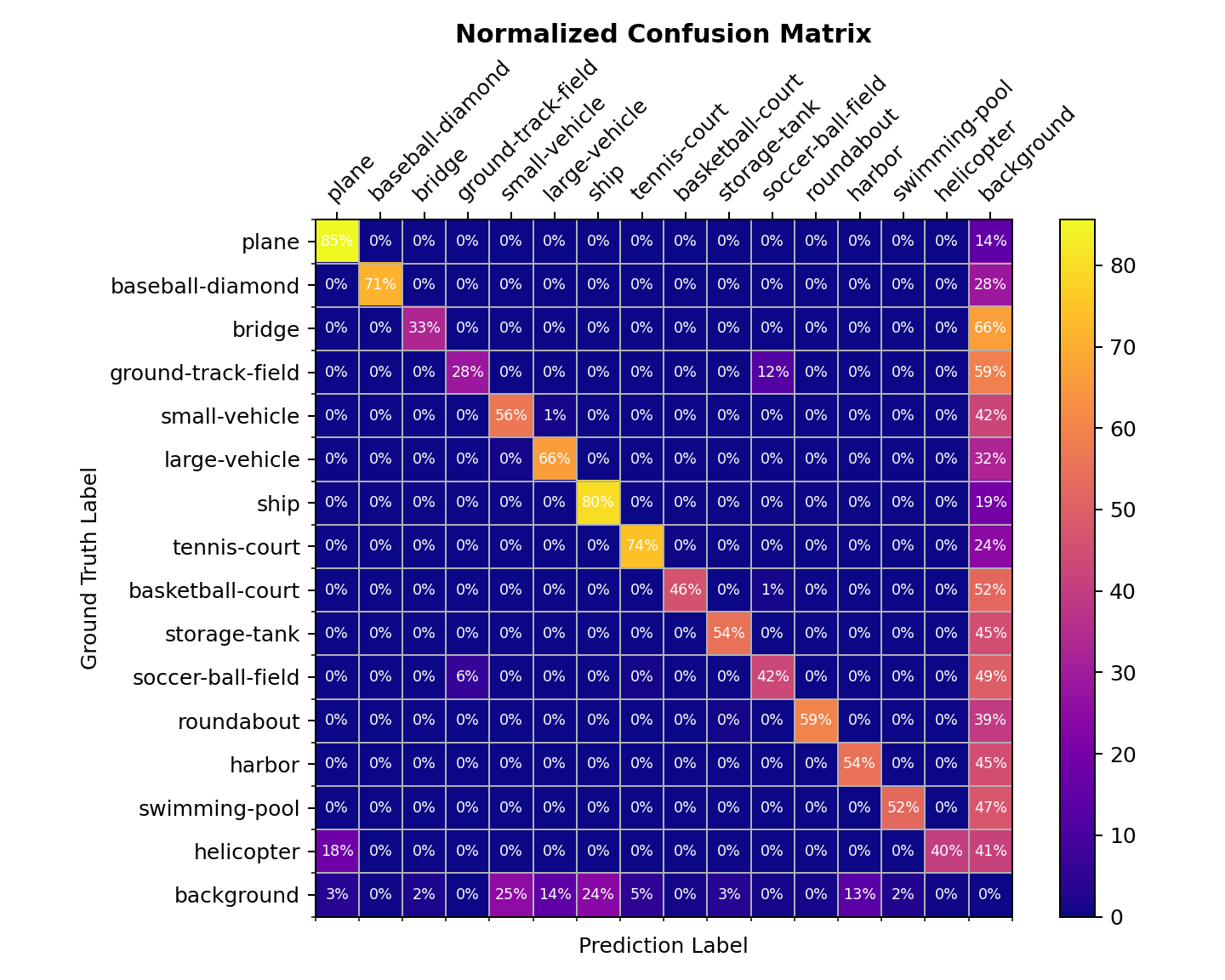
混淆矩阵¶
混淆矩阵是预测结果的概要
tools/analysis_tools/confusion_matrix.py 可以分析预测结果并绘制混淆矩阵。
首先执行 tools/test.py 将检测结果保存为 .pkl 文件。
之后执行
python tools/analysis_tools/confusion_matrix.py ${CONFIG} ${DETECTION_RESULTS} ${SAVE_DIR} --show
你会得到一个类似于下图的混淆矩阵: